

- Representing the structure and function of biological systems
via formal languages,
for description, simulation, analysis and (eventually) compilation.
-
What is Systems Biology? Wikipedia; Chemical&EngineeringNews
What is NOT Systems Biology? Yuri Lazebnik; Olaf Wolkenhauer
Computational Techniques: Executable Biology
Harvard movie: The Inner Life of the Cell
News
-
 CoSBi
CoSBi 
- SPiM Player release (stochastic π-calculus simulator with GUI)
- The BBSRC Centre for Integrative Systems Biology at Imperial College London
- The Microsoft Biology Foundation
BioComputing at Microsoft
Papers
Talks
Courses
- Molecular Programming - Tutorial (Microosft Research Cambridge, Feb 11 '10)
- Molecules as Automata - Open Lectures for PhD Students in Computer Science
 (Warsaw, March&May'09)
(Warsaw, March&May'09) - Molecules as Automata - International Summer School on Natural Computing (BNC'08)
- Artificial Biochemistry - Graduate Course (Trento, May 22-26 '06)
- Membrane Interactions - International School on Computational Sciences for Complex Systems in Biology (Rovereto, April 23 '04)
Position Papers and Notes
 Visualization in Process Algebra Models of Biological Systems (Data Intensive Computing)
Visualization in Process Algebra Models of Biological Systems (Data Intensive Computing)- Biological
Systems as Complex Systems (IST FET Complex
Systems)
- Process
Calculi and Biology (IST FET)
- Languages
for Systems Biology (Grand Challenges UK, GC1 InVivo<=>InSilico)
-
 InVivo<=>InSilico
(Ronan Sleep Ed.) (Grand Challenges UK, GC1 InVivo<=>InSilico)
InVivo<=>InSilico
(Ronan Sleep Ed.) (Grand Challenges UK, GC1 InVivo<=>InSilico)
Student Projects
- A Stochastic π-Calculus Models of MHC Class I Antigen Presentation
- Leonard Goldstein (with Luca Cardelli and Andrew Phillips), Computational Biology MPhil Project, Cambridge, August 26 2005.
- Generating
Definitions of Cell Cycles in π-Calculus
from Mathematical Models
- Rosemary Francis (with Pietro Lio'), Part II Computer Science Tripos, Cambridge, May 16 2005.
Publication Venues
- The HFSP journal
- The Transactions on Computational Systems Biology journal [Editorial Board Member]
- The Synthetic and Systems Biology journal
- The Journal of the Royal Society Interface
- The CMSB Conferences
Tools
-
DNA Strand Displacement Simulator
We present a programming language for designing and simulating DNA circuits in which strand displacement is the main computational mechanism.
- A programming language for composable DNA circuits
- Run it in your browser: Visual DSD
-
Stochastic π-Calculus Simulators
The underlying model for stochastic π-Calculus is continuous time Markov chains, including infinite-state systems.
Executing a stochastic π-Calculus program involves at each step computing a set of possible communication events
between pairs of processes, and choosing one of the events (and its specific process continuations) according to
exponential distributions, e.g. by Gillespie. In traditional (non-stochastic) pi-calculus the choice of events is
nondeterministic: the original motivation was the study of nondeterministic systems.
Each stochastic π-Calculus process can be seen as a state automaton, which coordinates its state transitions by
communicating with other automata in a compositional way (i.e. it is not necessarily a single gigantic automata
for the whole system). The various automata might not be finite-state and may evolve in unbounded ways, and
even create new communication channels and new automata. The characteristic feature of π-Calculus, as opposed
to previous process calculi, is the ability to dynamically generate new communication channels, which can be used
in a number of ways and turns out to be an extremely flexible modeling device.- SPiM (Andrew Phillips)
- SPiM Example: MAPK Cascade
(Chi-Ying F. Huang and James E. Ferrell, Jr., Ultrasensitivity in the mitogen-activated protein cascade, PNAS 93, 10078-10083, 1996). - SPiM Example: Evolved Gene-Protein Networks
(Paul Franois and Vincent Hakim, Design of genetic networks with specified functions by evolution in silico, PNAS (101)2, 580-585, 2004). - BioSPI (Regev, Shapiro, Silverman)
Essential Bibliography
- Molecular Biology

- Genetic Switch: Phage Lambda
Revisited. Third Edition (2004)
Mark Ptashne, Cold Spring Harbor Lab. ISBN: 0879697164 (amazon.com) - Molecular Cell Biology. Fifth Edition (2003)
W H Freeman, ISBN 0716743663 (amazon.co.uk) - Molecular Biology of the Cell. Fourth Edition (2002) Garland, ISBN 0815332181 (amazon.com)
- Genetic Switch: Phage Lambda
Revisited. Third Edition (2004)
- Process Algebra
- Wikipedia article on π-Calculus (quick reference)
- A Primer on the Stochastic p-Calculus Appendix A and B of: Compositionality, Stochasticity and Cooperativity in Dynamic Models of Gene Regulation. Ralf Blossey, Luca Cardelli, Andrew Phillips, HFSP Journal.
- Communicating and Mobile Systems: The π-Calculus.
(Introduction) Robin Milner.
Cambridge University Press, ISBN 0 521 65869 1, 1999. - An Introduction to π-Calculus.
Joachim Parrow.
In Handbook of Process Algebra, ed. Bergstra, Ponse, Smolka, pages 479-543, Elsevier 2001.
- Stochastic Process Algebra
- Interactive Markov Chains. Holger Hermanns. Springer Lecture Notes in Computer Science, vol 2428 (2002)
- Stochastic π-Calculus. Corrado Priami. The Computer Journal 38(7): 578-589 (1995)
- Biochemical Stochastic π-Calculus (Application of a stochastic name-passing calculus to representation and simulation of molecular processes). Corrado Priami, Aviv Regev, Ehud Shapiro, William Silverman. Information Processing Letters 80 (2001) 25-31.
- The StoPi-calculus and Simulator. Anders Bloch, Bjrn Haagensen, Michael Korsbk Hyer, Steffen Uls Knudsen. Aalborg University, Department of Computer Science, 30 May 2003.
- A Correct Abstract Machine for the Stochastic Pi-Calculus. Luca Cardelli and Andrew Phillips, Proceedings of BioConcur 04.
- Stochastic Modeling
- The p-calculus as an Abstraction for Biomolecular Systems. Aviv Regev and Ehud Shapiro. In G.Ciobanu, G.Rozenberg (Eds.) Modelling in Molecular Biology. Springer, 2004: 219-266.
- Biomolecular Processes as Concurrent Computation. Ehud Shapiro. 2001 Course at the Weizmann Institute of Science, Israel.
- Cellular Abstractions: Cells as Computation. Aviv Regev and Ehud Shapiro. NATURE vol 419, 2002-09-26, 343.
- Gene Regulation in the Pi Calculus: Simulating Cooperativity at the Lambda Switch. Cline Kuttler, Joachim Niehren, and Ralf Blossey, Proceedings of BioConcur 03, ENTCS 2004.
- Cell Cycle Control in Eukaryotes: a BioSpi model. Paola
Lecca and Corrado Priami.
Proceedings of BioConcur 03, ENTCS 2004. - Concurrency in Leukocyte Recruitment. D. D'ambrosio, Paola Lecca, Corrado Priami and C. Laudanna. Trends in Immunology , vol. 25, 2004: 411-416.
- VICE: a VIrtual CEll. D. Chiarugi, M. Curti, P. Degano, and
R. Marangoni. Procs. of 2nd Workshop on Computational Methods
for Systems Biology, Paris, May 2004.
- Membrane Computing
- Membrane Computing: Brief Introduction, Recent Results and Applications. Gheorghe Păun and Mario J. Prez-Jimnez.

Links
Biochemistry Glossary | Prefixes and Suffixes
- Languages: SPiM | BioSPI UdiShapiro>papers | BIOCHAM | PEPA | PRISM | Charon | PML
- Databases: GatewayToPathways | CMBSlib | SMBL | KEGG | NCBI | GenomicObjectNet | SigPath Signalling | BioCarta Genes | BioCarta Pathways | PathBLAST
- Institutes: Institute for Systems Biology | GenomesToLife | Genoscope | Interdisciplinary Research Institute | European Bioinformatics Institute | MRC Laboratory for Molecular Biology | Cambridge Computational Biology Institute | INRIA CPBIO | INRIA ModBio
- Societies: ISCB International Society for Computational Biology | BITS Societa' di Bioinfromatica Italiana
- Journals: IEEE/ACM Transactions on Computational Biology and Bioinformatics | Springer Transactions on Computational Systems Biology | PNAS Proceedings of the National Academy of Sciences
- Funding Agencies: BBSRC | BBSRC Centers for Integrative Systems Biology | FP6 Life Sciences Genomics Biotech for Health
- Software: WindowsApps | Accelrys | EMBOSS | GEPASI / COPASI
- Groups: Bionformatics at Trento | Bioinformatics at Bologna | Interdisciplinary Research Institute at Lille | Hans V. Westerhoff | Algorithmic Botany
- Forums: BioSPI | Lille
- Projects: EUSYSBIO / European Systems Biology Initiative | EPSRC Integrative BiologyBirmingham
- Calculi: Stochastic pi-Calculus. C.Priami, The Computer Journal 38(7): 578-589 (1995)
- The Lipid
World model:
A Fission-Fusion Origin for Life. V.Norris&D.J.Raine: Orig Life Evol Biosph. 1998 Oct;28(4-6):523-37
The Lipid World. [PDF] Segre D, Ben-Eli D, Deamer DW, Lancet D,: Orig Life Evol Biosph. 2001 Feb-Apr;31(1-2):119-45 - Online Tutorials: Mass Action Law | Chemical Kinetics | Effect of Concentration on Reaction Rates and Orders of Reactions and Rate Equations | Concentrations and Reaction Rates | ProteinsCMBI | Gene Expression Modeling | Molecular Cell Biology (Freeman) | Metabolic Flux Analysis + Examples | How to Create a Model - Ordinary Differential Equations | Kinetic Modeling | National Health Museum Graphics Gallery
- Libraries: PubMed | The Quantitative Biology Archive
- Bioinformatics at

Quegli che pigliavano
per altore altro che la natura
maestra de' maestri s'affaticavano invano.
Those who took inspiration from other than nature,
the master of masters, were laboring in vain.
[Leonardo da Vinci - 1500]
Abstract Machines of Systems Biology
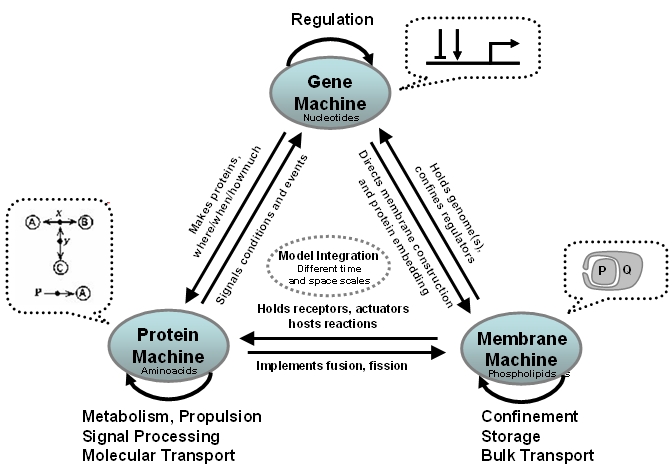
An abstract machine is a fictional information-processing device that can, in principle, have a number of different physical realizations (mechanical, electronic, biological, or software). An abstract machine is characterized by a collection of discrete states, and by a collection of operations (or events) that cause discrete transitions between states, possibly concurrently. The adequacy of this generic model for describing complex systems is argued, e.g., in D.Harel. "Statecharts: a visual formalism for complex systems." Science of Computer Programming 8:231-274. North-Holland 1987.
Biochemical toolkits in cellular biology (nucleotides, amino acids, and phospholipids) can be seen as abstract machines with appropriate sets of states and operations. Each abstract machine corresponds to a different kind of informal algorithmic notation that biologists have developed (inside bubbles). These machines operate in concert and are highly interdependent. Genes instruct the production of proteins and membranes, and direct the embedding of proteins within membranes. Some proteins act as messengers between genes, and others perform various gating and signaling tasks when embedded in a membrane. Membranes confine cellular materials and bear proteins on their surfaces. In eukaryotes, membranes confine the genome, so that local conditions are suitable for regulation, and confine other reactions carried out by proteins in specialized vesicles.
To understand the functioning of a cell, one must understand (at least) how the various machines interact. This involves considerable difficulties in modeling and simulations because of the drastic differences in the "programming model" of each machine, in the time and size scales involved.- Source: Abstract
Machines of Systems Biology (TCSB) [@Springer]
The Membrane Machine
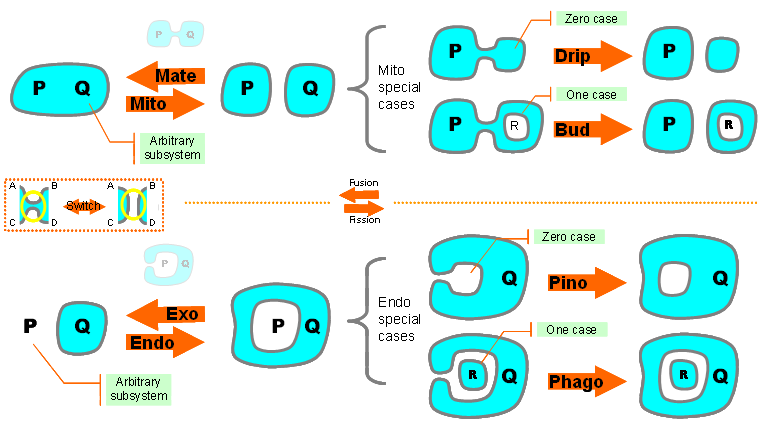
The basic operations on membranes, implemented by a variety of molecular mechanisms, are local fusion (two patches merging) and local fission (one patch splitting in two). In two dimensions at the local scale of membrane patches, fusion and fission become a single operation, switch. A switch is a fusion when it decreases the number of whole membranes, and is a fission when it increases such number.
When seen on the global scale of whole 2D membranes, switch induces four operations: in addition to the obvious splitting (Mito) and merging (Mate) of membranes, there are also operation, quite common in reality, that cause a membrane to eat (Endo) or spit (Exo) another subsystem (P). There are common special cases of Mito and Endo, when the subsystem P consists of zero (Drip, Pino) or one (Bud, Phago) membranes.Although this is an unusual computational model, the membrane machine supports the execution of real algorithms. In fact, some sets of operations, such as {Pino, Phago, Exo} are Turing-complete, and can encode the other membrane operations.
- Source: Abstract
Machines of Systems Biology (TCSB) [@Springer]
Biological Systems as Reactive Systems

Stochastic π-Calculus Simulation
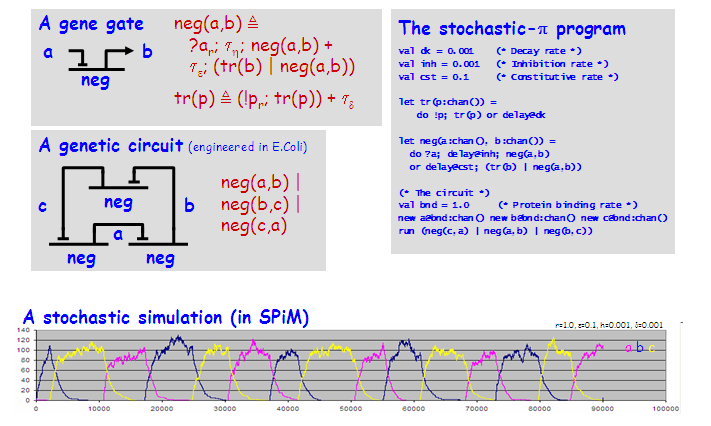
Impromptu Research Statement
Systems Biology is the emerging interdisciplinary study of complex biological systems from the point of view of relationships and interactions between different components. Many of these interactions are based on digital information (e.g. DNA) and on sophisticated information processing.
Biologists, especially now with the help of bioinformatics, are assembling
huge data bases of information about various biological structures (e.g. the
several Genome projects). This data helps, first of all, in understanding how
various biological processes and molecular mechanisms work; biologists are
making great and actually absolutely amazing progress in fundamental data
gathering and understanding. But understanding the high-level behavior of living
organisms seems to require more than understanding the individual nanomachines
they are made of: there are things to be understood that are not found in any
single piece of molecular hardware. Biological systems are "complex systems"
pretty much in the same sense as "complex software systems": layer upon layer of
complex control mechanisms that in essence do a lot of very sophisticated
information processing. I do not want to minimize this, but it is like trying to
reverse-engineer your PocketPC, and spending all the time in figuring out the
processor and the bus protocols: that's not going to tell you anything about how
it synchs Outlook! Because of that, system behaviors cannot be modeled
"analytically" very well by the usual techniques of continuous mathematics. Some
people (and some biologists) now claim that we need to achieve a better
understanding of this "systems" level, in order to understand how these things
truly work, and hence how to fix them other than by testing all possible
chemicals on them.
That kind of biological data is now being collected and made available on the
web. So, there is first a big problem of choosing a common representation for
the data. For genetic data, well, it's fundamentally all strings of AGCT
letters, but even that is a pretty hard problem because of all the auxiliary
information that goes with it. Similar databases and representation problems
exist for more complex structures, such as proteins. So there are plenty of
research problems already here. The next level up, and this is where I get into
the picture a bit, is to build databases of biological *processes*, e.g. of the
various signaling pathways that describe sequences of events that causes
something to happen in an organism. These are generally very concurrent
pathways, and some kind of process language is needed to describe them. It could
even be BPEL, or something similar, but is going to be quite different than
storing AGCT data. If one had such a library of interoperable biological
processes, one could pick and choose a bunch of these processes, combine them in
a simulator or in a symbolic analyzer (not unlikely a software analyzers), and
perform "in silico" experiments, e.g. to test drugs without having to synthesize
them. Moreover, if these biological control processes are so complex, with lots
of selected-in redundancy, it seems pretty unlikely that any single chemical
could have much effect on them, and not at the same time on lots of unrelated
things. Rather, an effective drug should itself be a multi-stage process that
reacts to the organism, and one would need to study how these processes
interact.
This kind of research activity is already going on in preliminary forms in
various academic and government projects, and one of my researcher goals is keep
track of those. At the same time I am trying to contribute to the idea of
describing biological processes, that is of finding "programming languages" that
can code them up effectively, for the various purposes of archival, analysis,
and simulation.
A long term vision in this field is one day to put all those processes together,
and simulate an entire organism, say a very small cell (which is itself
astoundingly complex). Such a project is at the level of a "grand challenge"
that would require an effort way beyond the Human Genome project. Some such
projects have been proposed in the past, but more in the area of differential
equations simulation of these systems. Well, we don't use differential equations
to code up algorithms, and there is reason to believe that they are just as
unsuitable for describing critical aspects of decision processes in living
organisms.
So, this is where the things we regularly do, computer software, may have
something new to contribute: at the "system software" level of understanding.
Biology is not just exciting science, but exciting "computer" science, in the
broad sense of the study of information. Biological systems (of all kinds) are
fundamentally information processing systems that happen to run on wet hardware.
Even at the lowest level, the genetic code, that's digital information (1
Megabyte in each E.Coli bacteria, 800 Megabytes in each human cell), and reproduction is
almost by definition making copies of information. And it goes all the way up
from there. I am sure that software will play a critical role, one way or
another, either as a new paradigm or as a tool to assist biologists in ways that
are yet unthinkable. And I am also sure that, as soon as we learn how to build
these wet machines for ourselves, there will be a lot of programming to do.
